An Image is Worth 16x16 Words Transformers for Image Recognition at Scale
이 내용은 모두의 연구소 - 슬로우페이퍼 시간에 토론한 내용을 바탕으로 작성하였습니다.
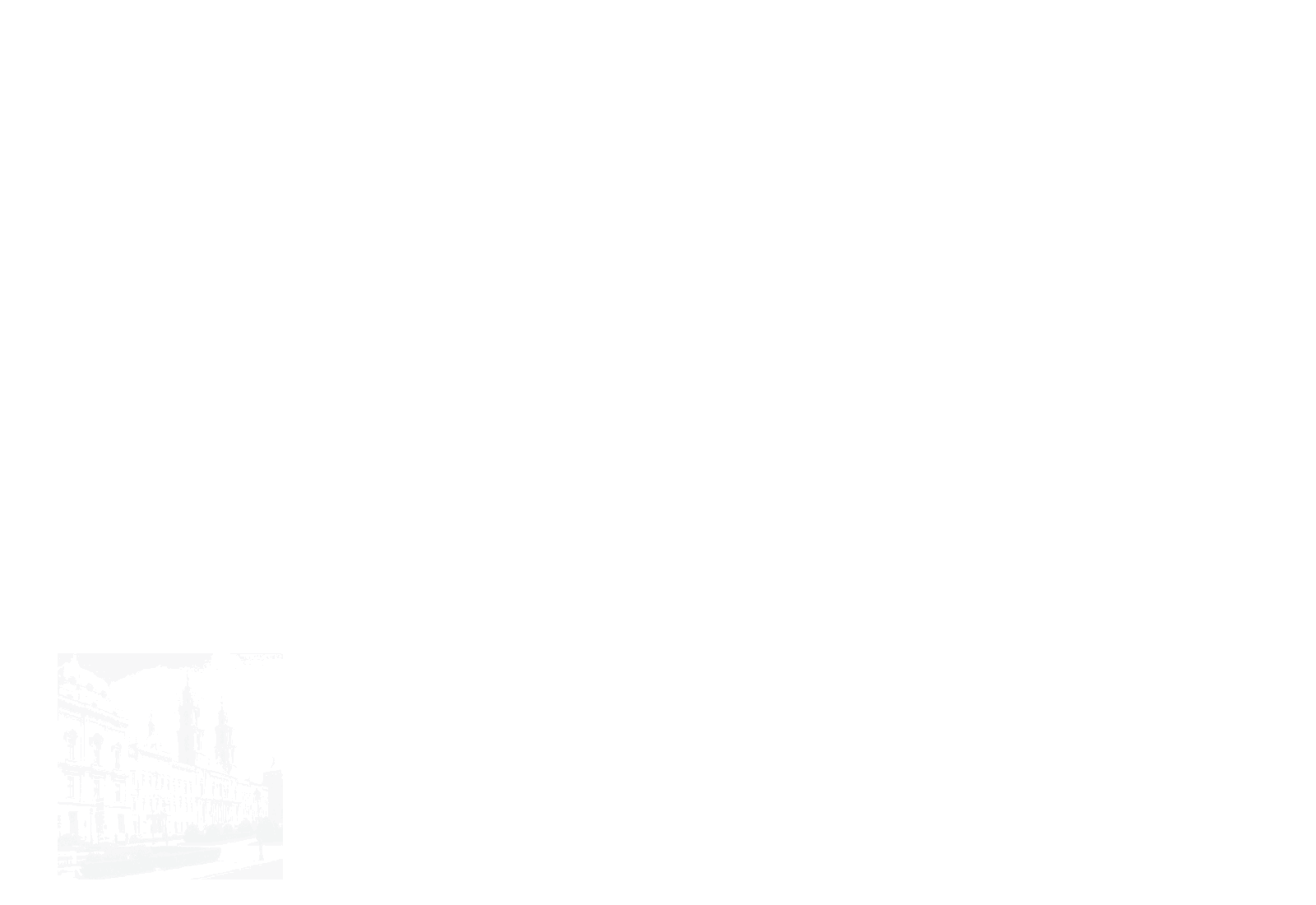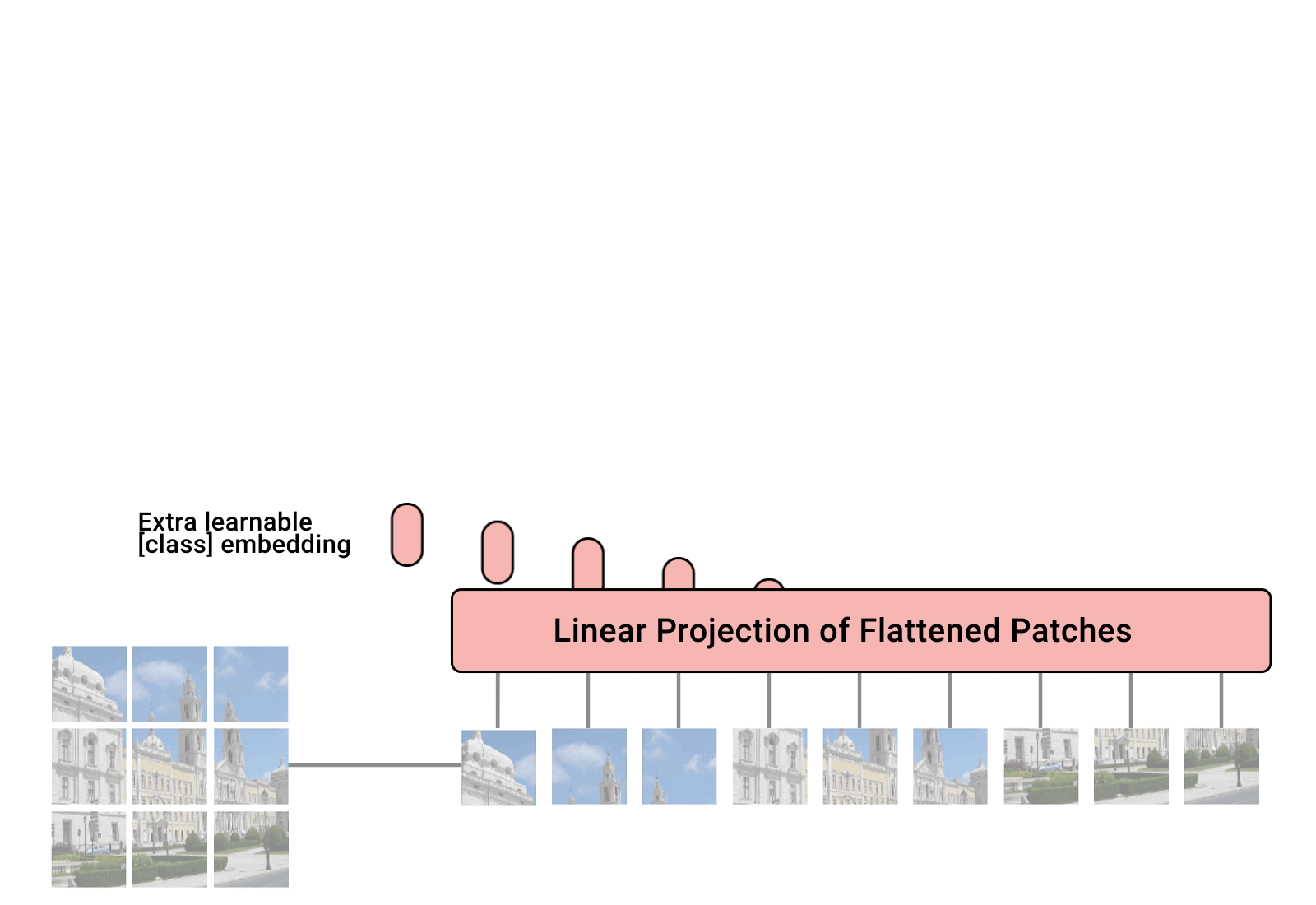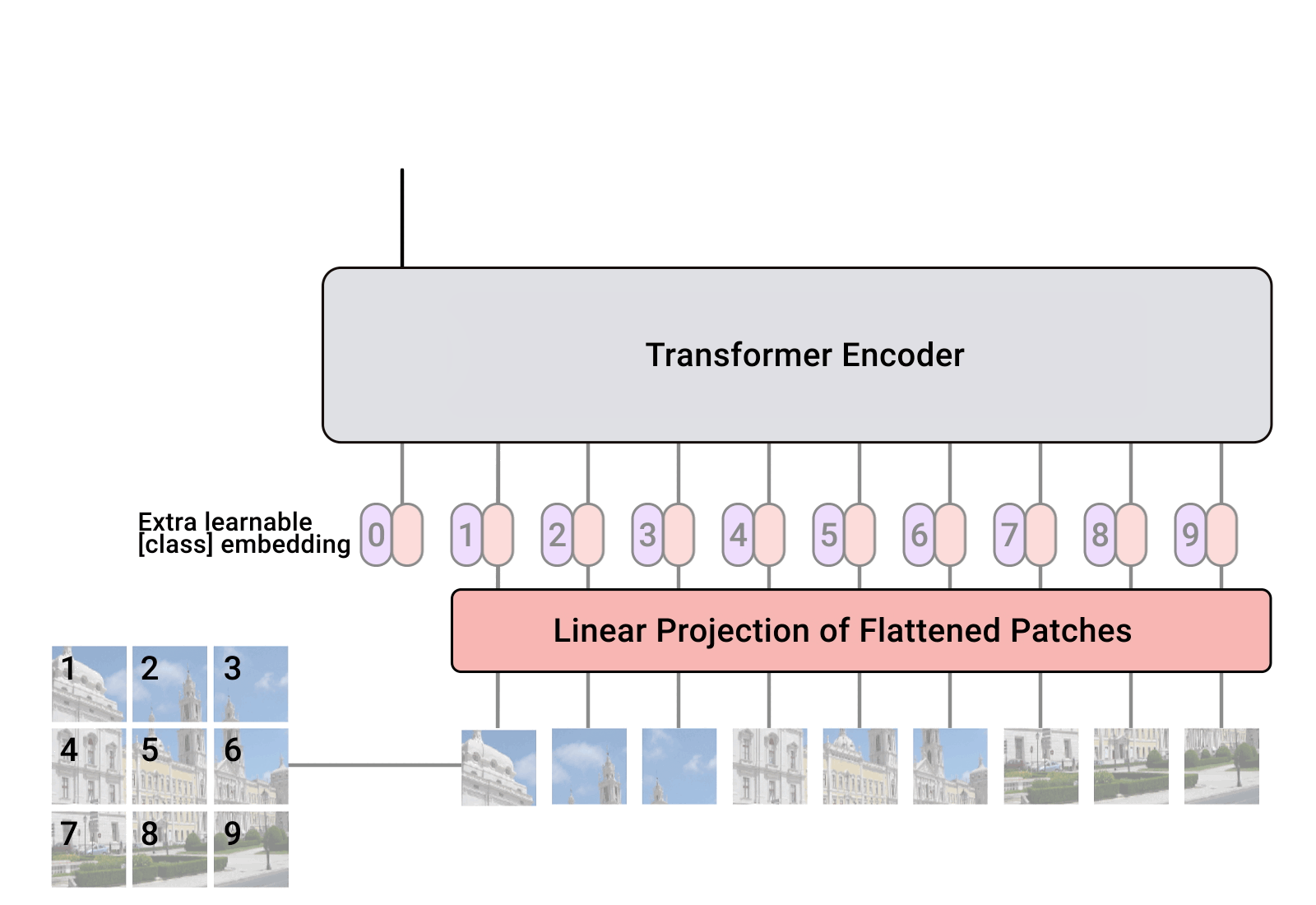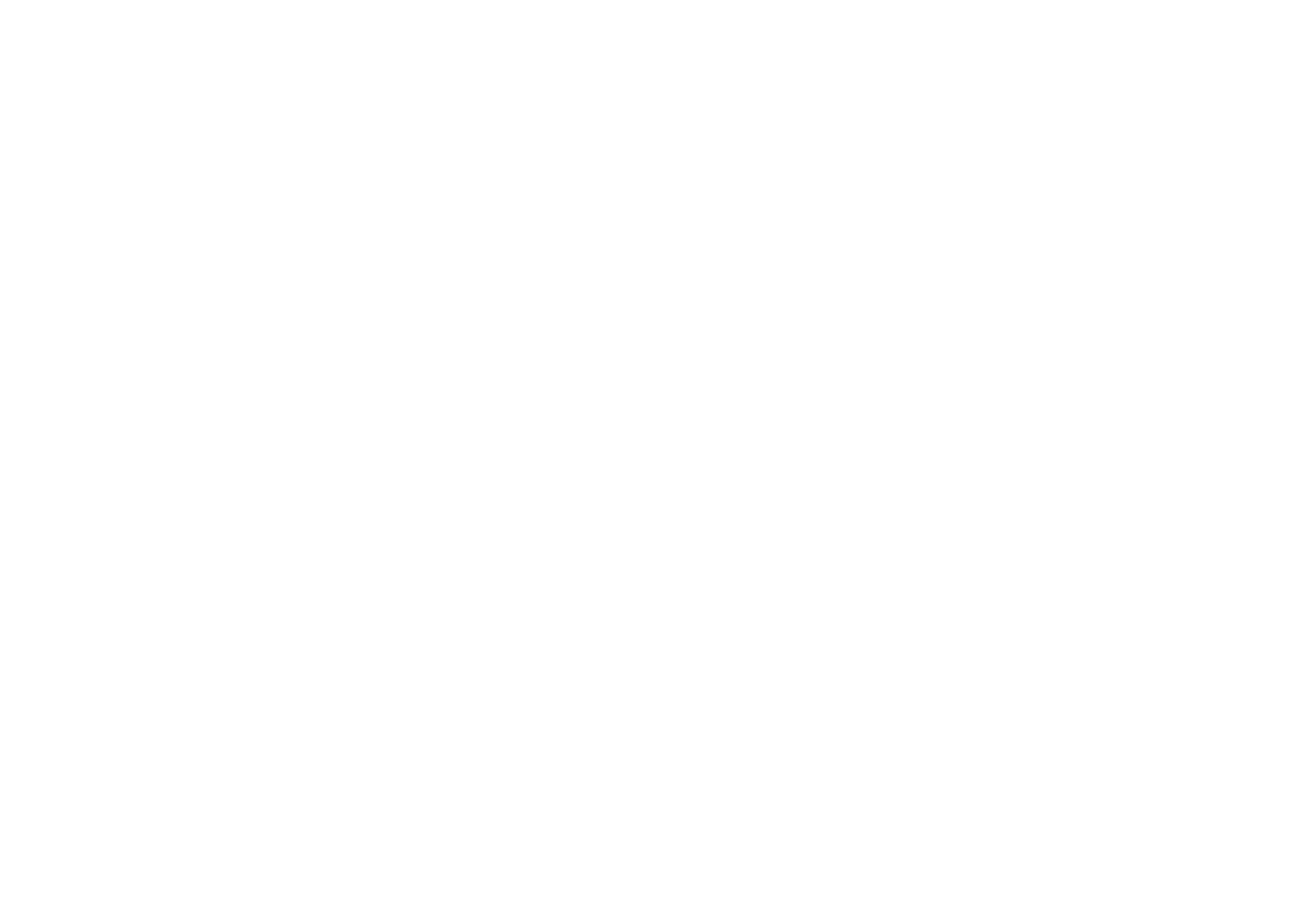
NLP에서는 사실상 표준이 되어버린 Transformer. 이 NLP Transformer 아키텍처를 최대한 비슷하게 Vision에 적용한 Vision Transformer(ViT) 모델에 대해 알아봅시다.
Embedding

ViT에서는 2가지의 embedding을 학습합니다.
- 이미지를 sequential하게 만들기 위한 patch embedding
- sequential한 이미지의 위치를 기억하기 위한 positional embedding
patch embedding
ViT는 NLP Transformer에서 벡터로 표현된 문장을 한번에 입력하는 것처럼 이미지를 패치로 나눠서 각 패치를 단어처럼 다룹니다. 위의 그림처럼 이미지를 Flatten처리하여 Encoder에 집어넣습니다. 이 과정을 수식으로 표현한다면 아래와 같습니다.

- 원래 이미지는 Flatten한 뒤 ViT에 입력하는 것은 위같이 벡터로 처리하여 입력하는 것입니다.
아래의 patch embedding의 코드를 보면 구조를 더 직관적으로 알 수 있습니다.
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
self.patch_size = patch_size
super().__init__()
'''
self.projection = nn.Sequential(
# break-down the image in s1 x s2 patches and flat them
Rearrange('b c (h s1) (w s2) -> b (h w) (s1 s2 c)',
s1=patch_size, s2=patch_size),
nn.Linear(patch_size * patch_size * in_channels, emb_size)
)
'''
self.projection = nn.Sequential(
# using a conv layer instead of a linear one -> performance gains
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
)
코드의 주석처리한 부분을 보면 flat하게 만든 뒤 Linear Layer에 넣어주는 것을 알 수 있습니다. 이것이 논문에서 설명한 CNN을 사용하지 않는 pure Transformer의 모습입니다. 하지만 저 부분을 주석처리를 해놓은 이유는 ViT의 저자들이 더 높은 성능을 얻기 위해 Linear Layer를 Convolution Layer로 코드를 수정하였기 때문입니다. 이러한 이유로 Conv Layer를 적용한 후에 이미지를 flat하게 만들도록 순서를 바꿔준 것을 볼 수 있습니다.
positional embedding
ViT는 Self-Attention을 하기위해 이미지를 patch 단위로 잘라 sequential하게 만들어 주기때문에 이미지의 위치 정보를 유지하는 positional embedding이 필요합니다. 이는 BERT의 [CLS] token과 동일합니다. 아래의 식처럼 패치에 positional embedding을 더해주는 구조를 갖게됩니다. positional embedding 또한 학습이 가능합니다. 위치를 넣을 때는 2D와 1D간의 큰 차이가 없기때문에 1D로 들어가게 됩니다. 각 포지션 x에 patch embedding projection E가 곱해지고 positional embedding이 더해지게 됩니다.


Transformer의 input으로 들어가는 모습을 보면 맨 앞의 학습 가능한 cls embedding이 함께 들어가고 후에 MLP Head를 통과해 classification에 사용됩니다.
Architecture

**Transformer의 Encoder 부분을 갖고있으며, 이는 BERT와 유사합니다. ** Original Encoder와 다른점은 2가지 입니다.
- Pre-Norm : Multi-Head Attention/ MLP의 전에 위치해있다.
- GELU : MLP는 2단으로 활성화 함수로 GELU를 사용한다.
ViT의 Architecture를 코드로 보면 아래와 같습니다.
def forward(self, img, mask = None):
p = self.patch_size
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = p, p2 = p)
x = self.patch_to_embedding(x)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x, mask)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
먼저 앞서 설명한 patch embedding과 positional embedding 후 transformer에 들어갑니다.
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Residual(PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout))),
Residual(PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout)))
]))
def forward(self, x, mask = None):
for attn, ff in self.layers:
x = attn(x, mask = mask)
x = ff(x)
return x
Transformer를 더 자세히 살펴보면, 위 그림의 구조를 depth(Lx)만큼 반복한 다는 것을 알 수 있습니다.
Transformer의 값은 MLP Head로 들어가 결과 값이 나오게됩니다. 이때, MLP Head에 들어가는 값은 cls_token의 결과입니다.
Hybrid Architecture
 이미지를 패치로 분할하는 대신 ResNet의 intermediate feature map에서 input sequence를 형성할 수 있습니다. 이는 저희가 다음 시간에 공부할 DETR의 구조와 비슷합니다. 아래의 그림은 DETR의 아키텍쳐 중 앞 Encoder 부분입니다. 빨간 네모의 부분을 backbone이 대체합니다.
이미지를 패치로 분할하는 대신 ResNet의 intermediate feature map에서 input sequence를 형성할 수 있습니다. 이는 저희가 다음 시간에 공부할 DETR의 구조와 비슷합니다. 아래의 그림은 DETR의 아키텍쳐 중 앞 Encoder 부분입니다. 빨간 네모의 부분을 backbone이 대체합니다.
References